Machine Learning on Web Logs
 Jeremy Greze
Jeremy Greze

Almost every action we do on the Internet or on mobile applications is recorded in files known as web logs. These logs can be very voluminous, providing a classic example of Big Data.
Data science and Machine Learning algorithms can provide a way of making value from web logs. At the OVH Summit on the 11th of October, I presented a workshop on getting value out of web logs through Machine Learning with Dataiku DSS. In this article, I will run through the aspects of that presentation.
In web logs, each row (or record) represents a user’s action (e.g, opening a page, an error that occurs, or something else) typically with the following information:
- Date and time of the action
- User’s IP address
- Details of the action
- Diverse information on the context (user-agent, etc.)
From this fairly raw data, which is often stored in flat files in a compressed format, the aim is not to calculate descriptive statistics, such as the number of visitors per country or the conversion rate. For this, Google Analytics or Piwik are very good tools.
Instead, the objective is to resolve advanced problems that are specific to the business context of the company. Data science allows us to produce use cases such as client segmentation or product recommendation. I will recap on some of these at the end of the article.
The classic first step in a project with web logs is to prepare the data. For example:
- Filter and retain certain actions
- Identify (or parse) dates and make use of them (differences between two dates, etc.)
- Clean missing or abnormal data
- Geographically locate the IP address (geoip)
- Work with certain values such as the user agent of a navigator
- Categorize certain actions (based on the URL, for example)
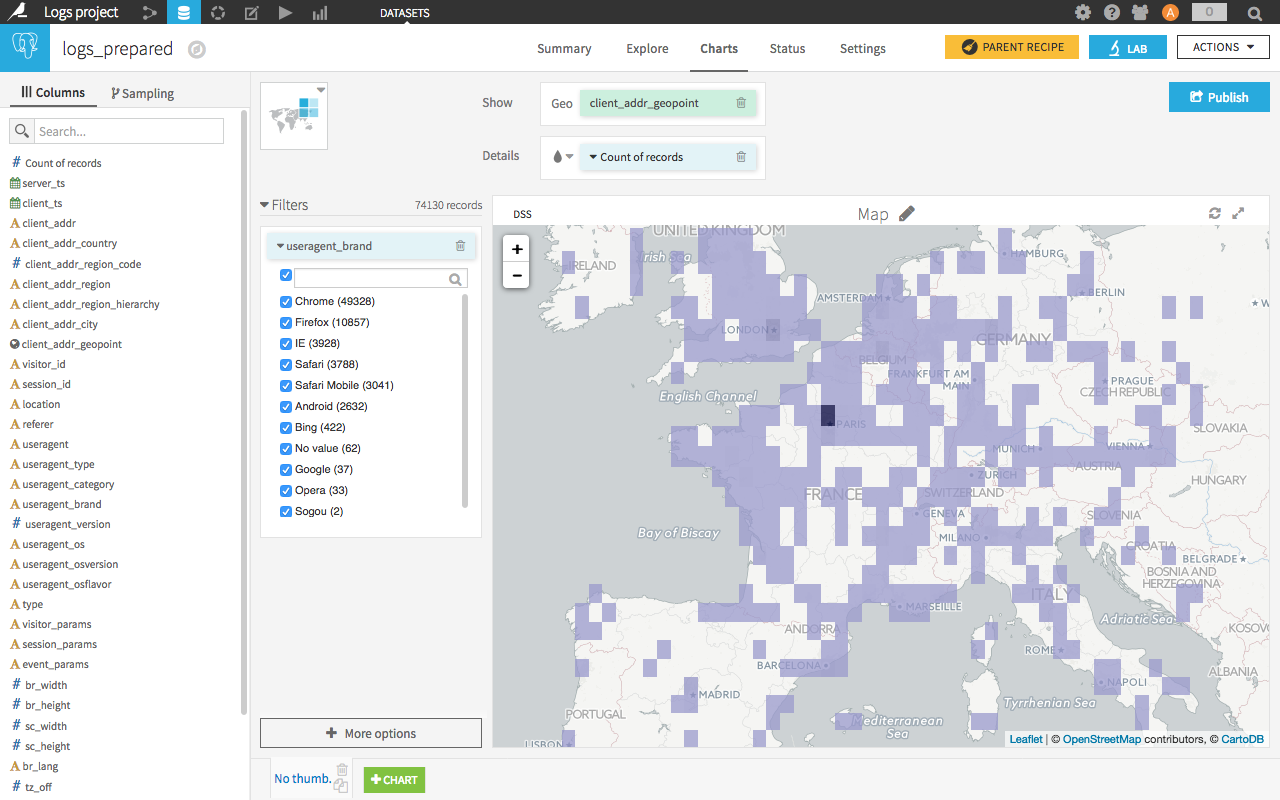
It is possible to do most of these actions visually, that is to say without using code, with Dataiku DSS. For example, here we split dates and geographically locate the IP address:
Throughout the data preparation, we can of course use graphics and descriptive statistics in order to understand the variables that we are manipulating.
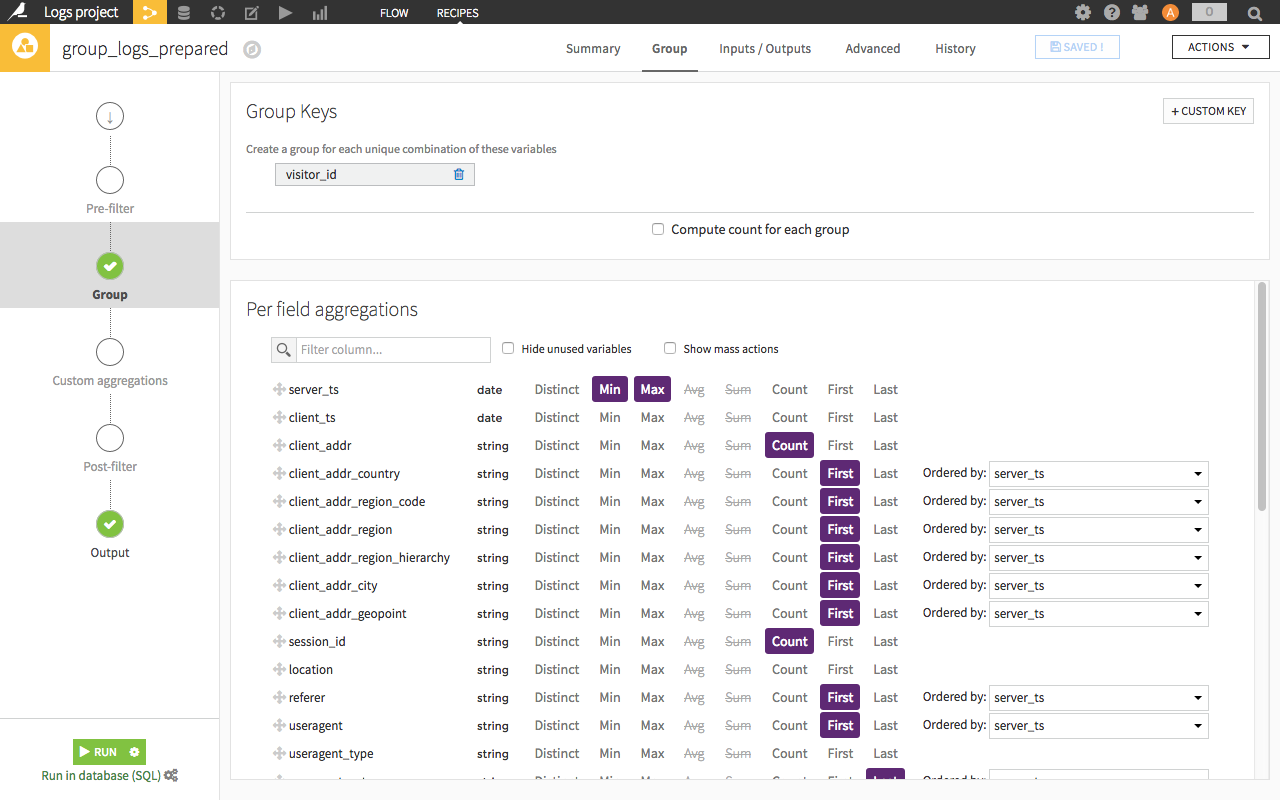
The second stage is the reduction of dimension. The idea is to pass from the action level to the user level with a summary of the user’s actions. In order to apply a machine learning algorithm, we need each row to represent a user (I speak here for the majority of cases).
To do this, we will use the visual recipe ‘group by’ to group rows and construct the “summary” of the user. We construct variables which will qualify the users using visual tools or SQL code.
A few examples of variables obtained for each user:
- Number of actions
- Dates of the first and last actions
- Counts of occurrences of some actions (more advanced: count of occurrences through a sliding time window)
- Statistical indicators of actions or their associated values (means, quartiles, deviations...)
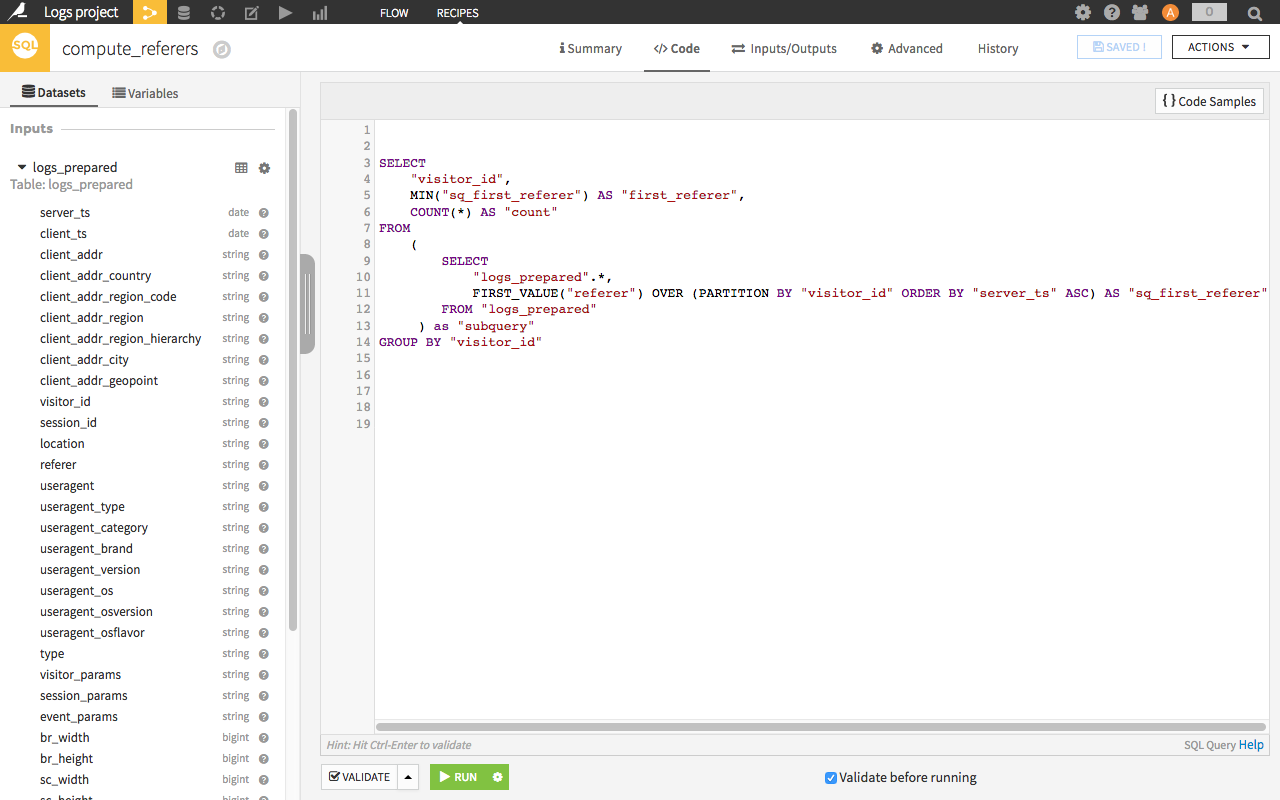
Note that these transformations can be executed in database using an SQL base, a Hadoop or Spark cluster (via Hive or Impala).
These variables that we are building are very important. They allow us to “feed” the algorithm with user characteristics and behaviors. Of course, adding external information to web logs brings many advantages, as is the case for CRM data. Technically, this can be a simple left join on the client ID using a CRM table to combine the data with the inscription date, the number of sales or information about the client profile.
Once we have a dataset with the users’ data and several variables, we can employ Machine Learning algorithms. The objective is to find correlations or indicators in the data, which are not necessarily visible to the human eye, in order to resolve a defined problem.
Two families of algorithms:
- Supervised Machine Learning: We choose a target variable that we want to explain, and the algorithm finds the correlations in other variables in order to explain or predict the target variable.
Example: predicting a conversion. - Non-supervised Machine Learning: The algorithm finds similar rows (users in our case). The segmentation is automatically calculated from differences in the data. Is is also called clustering.
Example: splitting user behaviours.
In Dataiku DSS, we can perform this work in the visual interface (but also in Python or R). In the short video below, we take the example of predicting a conversion on a website. We choose the algorithms (one linear, one based on decision trees) and the variables to be included (we leave the choice to default), and we change a numeric variable into a categorical variable. We then launch the learning process on our data (this can take a while).
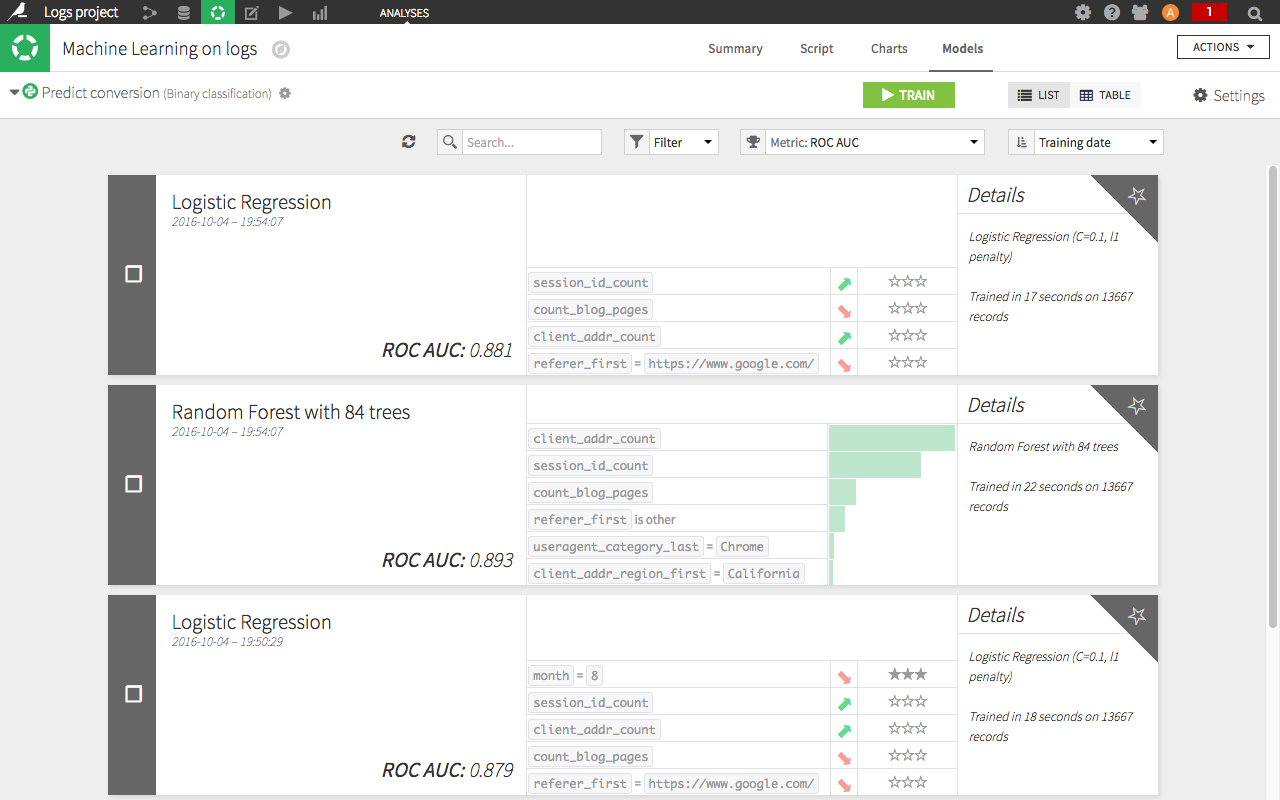
When the learning process is over, we look at the performance of the models created by the algorithms. A ROC AUC of 0.881 tells us at first glance that the model is performing quite well (simply speaking, between 0.5 and 0.7 is okay, between 0.7 and 09 is good, and between 0.9 and 1 is suspicious because it's too good).
Similarly, we look at what the model has learned from the data. Without going into detail, we see here (in the screenshot) a positive correlation between the number of sessions on the website and the chance of conversion, as well as a negative correlation between visits coming from Google and the chance of conversion.
Companies that wish to exploit their web logs usually fall into the following use cases:
- Optimization of conversions (sales, downloads…)
- Working on recommendations, i.e. to suggest products or content that have the best chance of appealing to consumers.
- Calculating client satisfaction scores or the risk of churn
- Segmentation of behaviours
- Detecting suspicious behaviour
These use cases will generate added value compared with descriptive analyses. The automation of obtaining results usually generates some pretty cool uses such as personalized emails, up-to-date scoring in CRM that the marketing team can use in their daily work, etc.
The presentation slides are available to download (in French). Of course, you can download the free version of Dataiku DSS to play with your web logs.
I suggest that you use two complementing resources: a connector that I have developed to retrieve logs of websites hosted by OVH in Dataiku DSS, and an open-source web tracker to embed in a website to collect logs. This tracker, WT1, is very practical and performs pretty well (20,000 events per seconds on a common sever).
Other than that, it was our first participation at the OVH Summit and we will be back :)