A Fun Side Project: Real-Time Classification of Twitter Accounts
 Jeremy Greze
Jeremy Greze

Today I launched a little side project, Human Or Company, a web page where anyone can enter a Twitter username and instantly determine whether that username belongs to a person or a company.
This is a modest (and fun!) side project that is a good example of how a website based on real-time machine learning predictions can work.
In this post, I will share how I created the model behind the algorithm, the features that influence the classification, and how I built the site to respond to real-time requests.
The original idea
I work as a Product Manager at Dataiku, a data science software editor. And I like building products or scripts around APIs from different online services, including Twitter, trying data science models on a variety of datasets, for work but also for fun.
For a few months now, I've been thinking about building an open demo for the real-time prediction capacity of our software. Many people I meet are confused about "real time" applications in Machine Learning so I wanted to build an example. Also, this is just fun to get a predictive-model result within a second in my opinion :)
I found in a Kaggle competition a data set generated in 2015 by CrowdFlower containing approximately 20,000 Twitter usernames, their typology (male/female/brand) and some other information. CrowdFlower wrote a blog post about the patterns (words, colors, and phrases) which can determine the account user's gender. The project was well conceived and it allowed for finer classification and improvement. I wanted to make the problem simpler and so I made the decision to focus on the classification of individuals versus non-individuals.
From the dataset, I kept only two columns: the twitter user name and the label (individual/non-individual). I wrote a Python script to enrich each Twitter user with their full name, bio, location, external link, number of tweets, followers, followings and favorites. At the end, I got a list of 14,000 users, probably because some users were deleted or blocked since 2015.
I ran very quickly a first predictive model to see if I could derive any interesting value from this dataset. For non-technical readers, the idea behind this is to see if there is any pattern in the data (a word in the bio description, the numbers of tweets, etc.) that indicates whether the twitter account belongs to a human or a company.
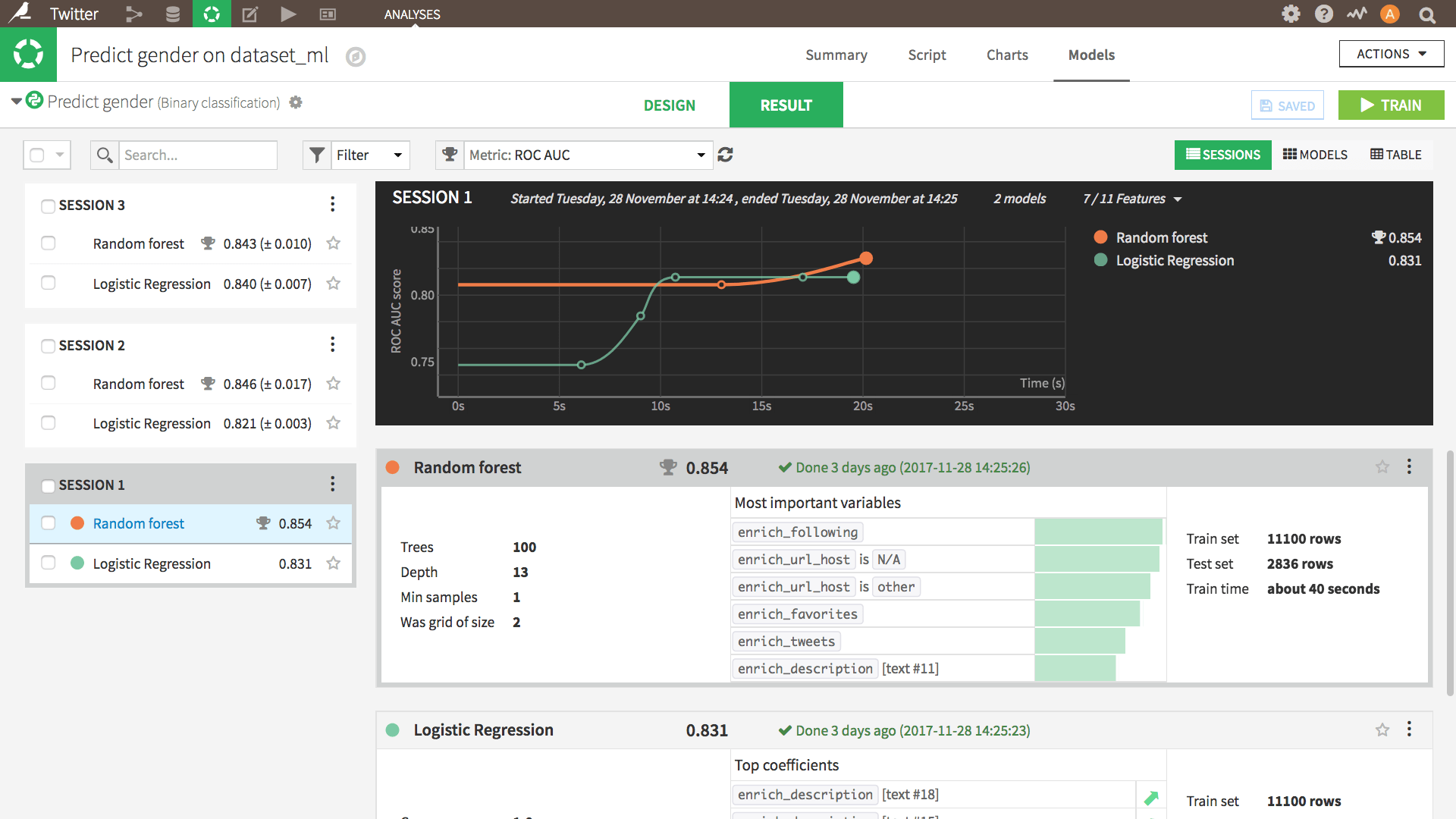
The answer was yes! The first model (using a logistic regression classifier) gave me an accuracy response of more than 80% and an AUC of 83%.
The results were also meaningful. The probability of an account belonging to a company increases with the number of tweets, of likes, or of followings. If you have in your bio a link to an instagram.com or a linkedin.com, your are more likely to be human.
Getting to a real project
After creating a machine learning model, you can use it to predict new values. Put simply, you get a mathematical formula that you can later use to generate a score on any username.
So I picked some twitter usernames that were not in the original dataset, I applied my enrichment function to get all the deviated variables, and I applied my model to get the prediction. There were some errors but in general it worked very well.
The first version of the algorithm only use very few variables to get the prediction. Here is the list:
- number of tweets
- number of followers
- number of followings
- number of favorites
- profile location
- profile description
- domain of the link of the profile
The bio profile is an important feature of the model. The text was normalized and reduced with the TF/IDF method. Some influencing words are "official", "my", "support", etc.
I have plenty of ideas to improve later the model. The profile image analysis is one of the most promising ones. A company very likely uses a logo, whereas an individual will tend to use a photo or an avatar. However, image recognition is more complicated and resource consuming. I want the prediction on the webpage to be fast (1 or 2 seconds max). To analyse an image, the script also needs a few hundred milliseconds to get the image from twitter. For the first release, I decided to keep it simple and not to do any image analysis.
In terms of models, I only compared the results between logistic regression and random forest. The two had a very similar AUC so I kept the logistic regression for the first release.
Then, I packaged the model into an API service to automate the predictions. With Dataiku DSS, that was easy.
I developed a web page that basically include a form and some JavaScript that sends the username to the API to get and display the result.
I deployed the project on a small server, I added a CDN with Cloudflare, and that was it. Ready for launch.
First version online!

You can try Human Or Company yourself at www.humanorcompany.com (UPDATE: website is no longer available).
Let me know on Twitter how it works for you. On my side, it works pretty well. Myself I get a score of 81% human, @dataiku is 52% company (almost a human! is it good or bad?). Overall, it does not look too bad for accounts in English.
I hope that it will show that "Machine Learning" or "Artificial Intelligence" (the trendier term) can be used in a simple and small project. Also, it gives an example that the model does not necessarily need to be created or trained in real time. In the case of Human Or Company, the model is prepared in advance and only the prediction is applied in real time. This is accurate enough in many cases, easy to maintain, and allows for assessment before going live.
Feel free to contact me with any question or feedback you might have. I will hopefully find some more time to make improvements on the model soon and release a second version.